Category-Level Articulated Object Pose Estimation
CVPR 2020(Oral)
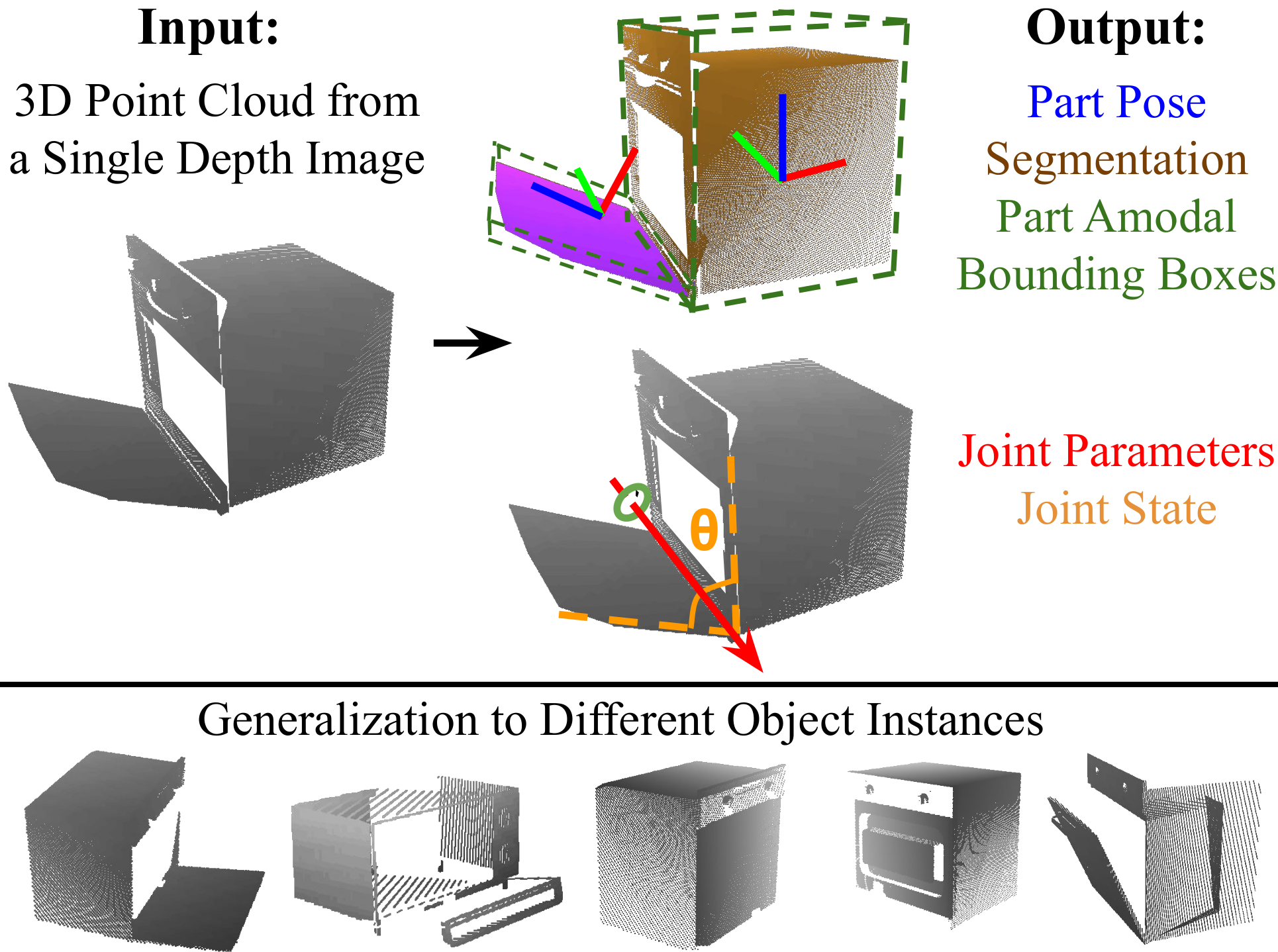
This project addresses the task of category-level pose estimation for articulated objects from a single depth image. We present a novel category-level approach that correctly accommodates object instances previously unseen during training. We introduce Articulation-aware NormalizedCoordinate Space Hierarchy (ANCSH) – a canonical representation for different articulated objects in a given category. As the key to achieve intra-category generalization, the representation constructs a canonical objectspace as well as a set of canonical part spaces. Thecanonical object space normalizes the object orientation,scales and articulations (e.g. joint parameters and states) while each canonical part space further normalizes its part pose and scale. We develop a deep network based on PointNet++ that predicts ANCSH from a single depth pointcloud, including part segmentation, normalized coordinates, and joint parameters in the canonical object space. By leveraging the canonicalized joints, we demonstrate: 1) improved performance in part pose and scale estimations using the induced kinematic constraints from joints; 2) high accuracy for joint parameter estimation in camera space.
Video
Results
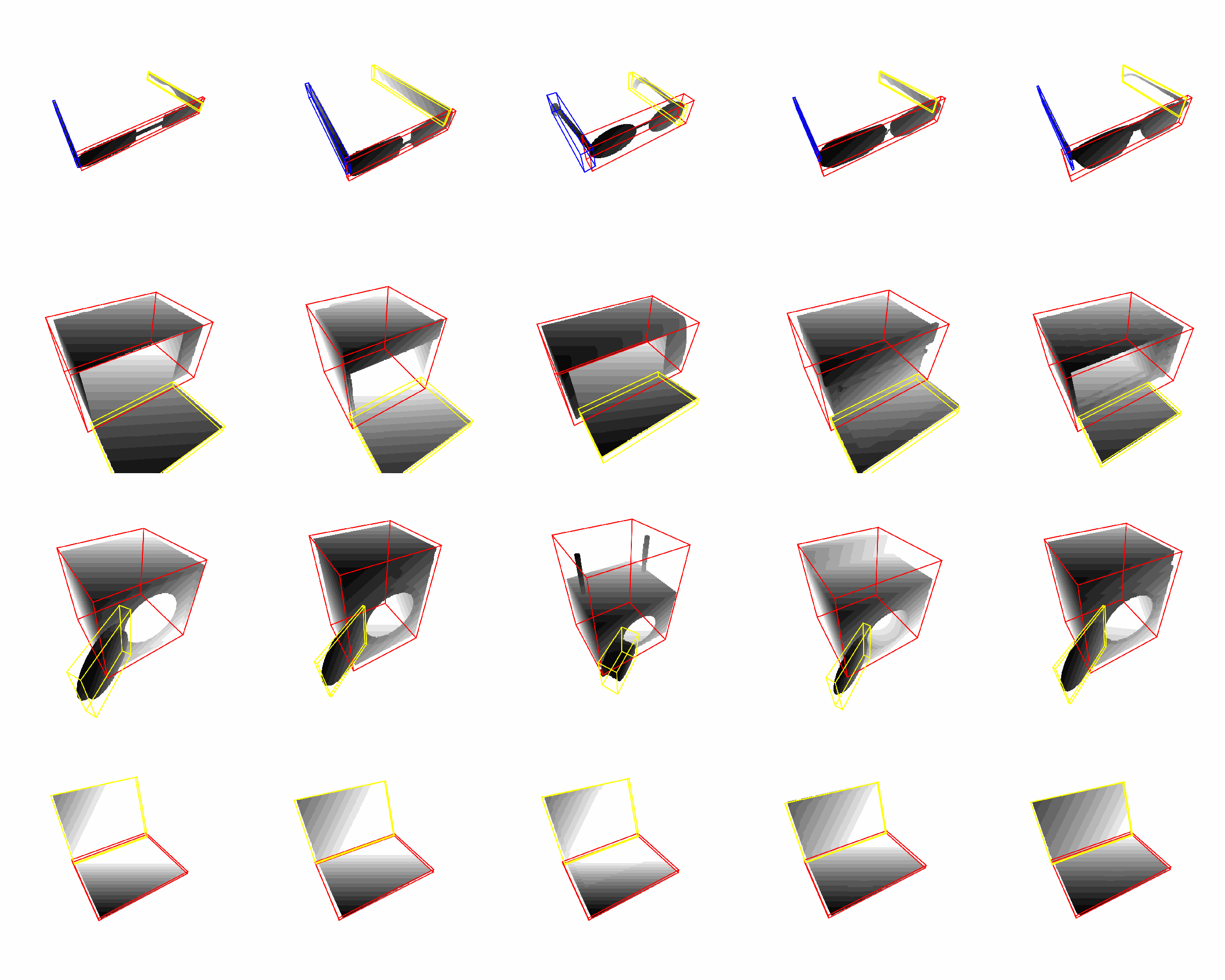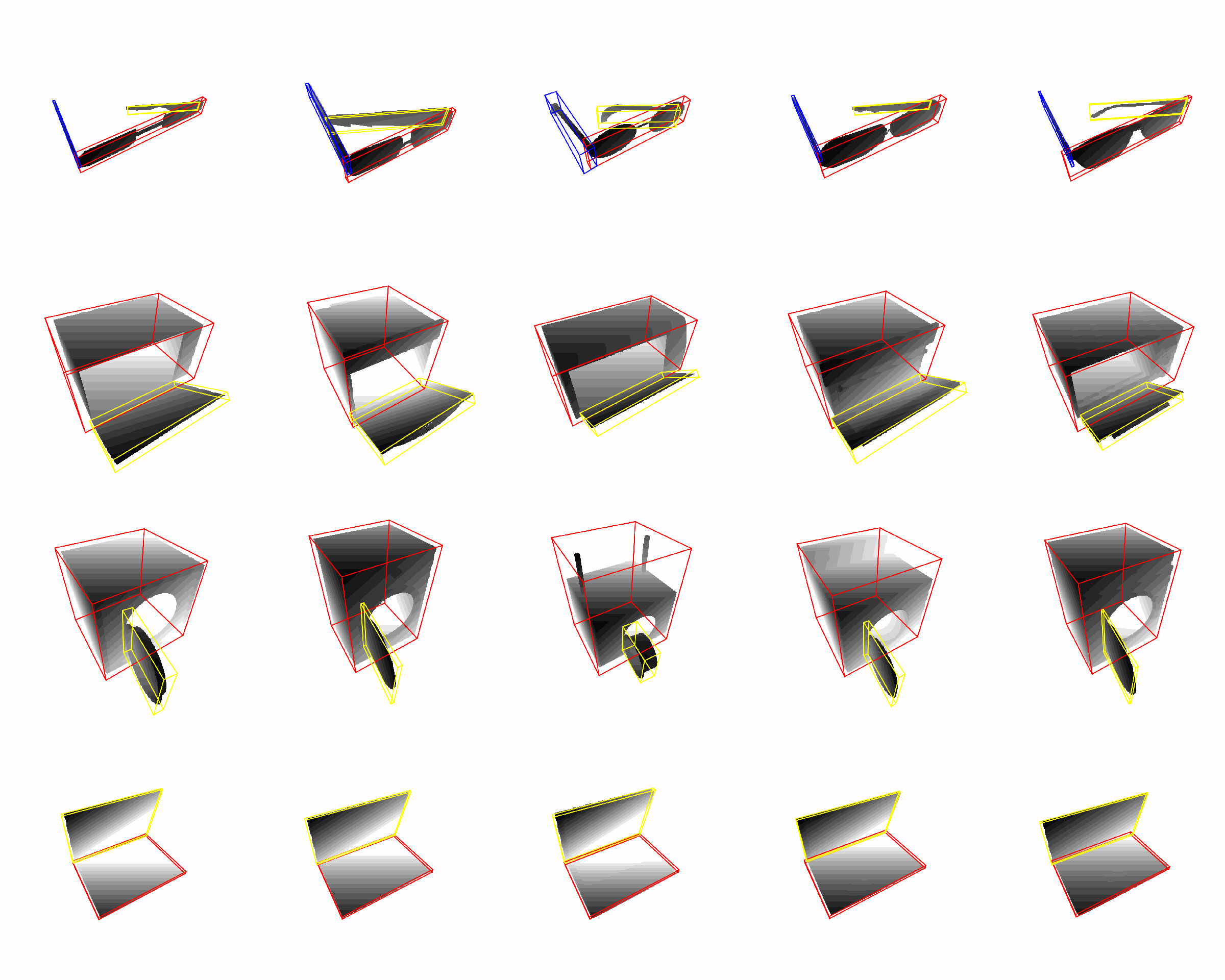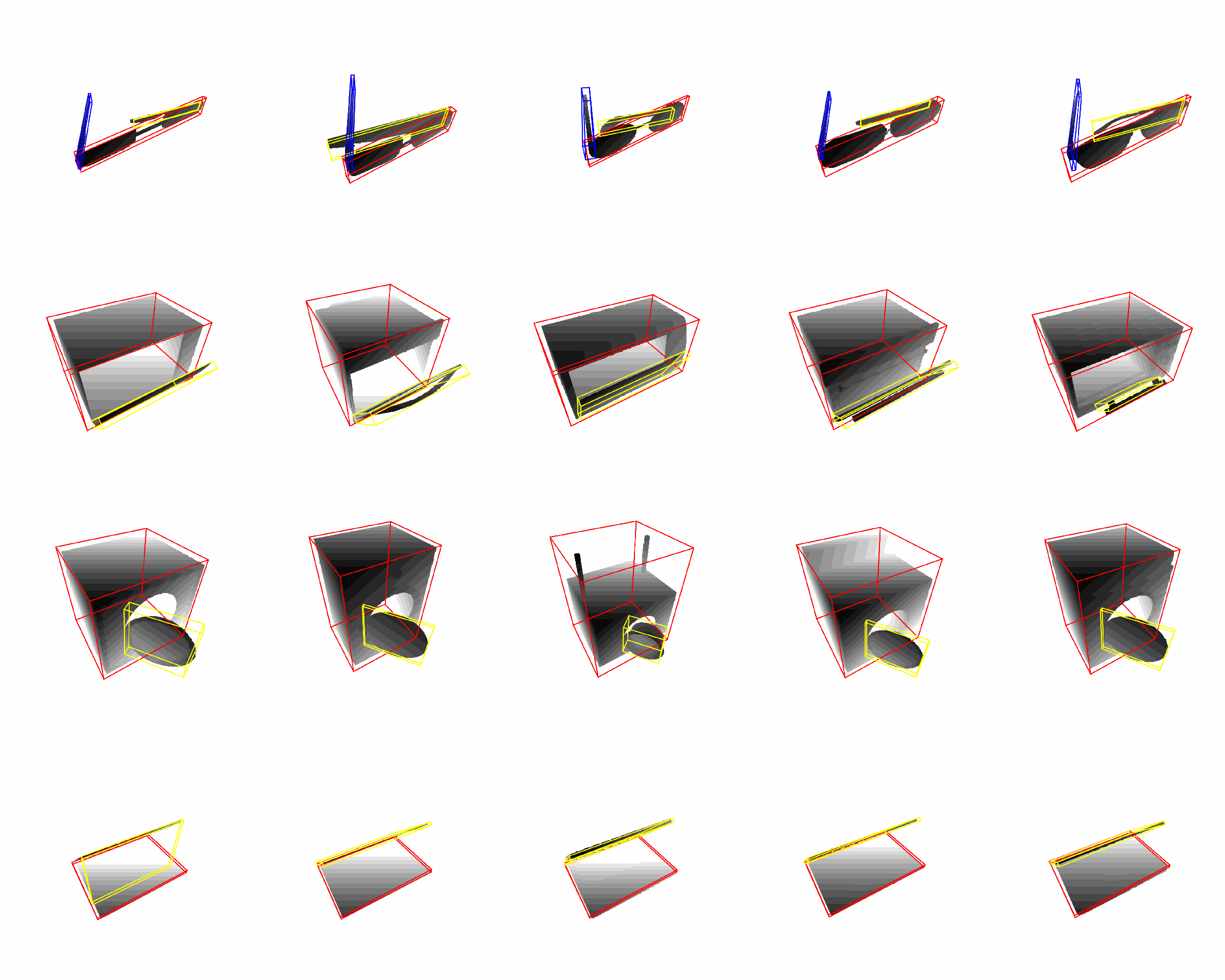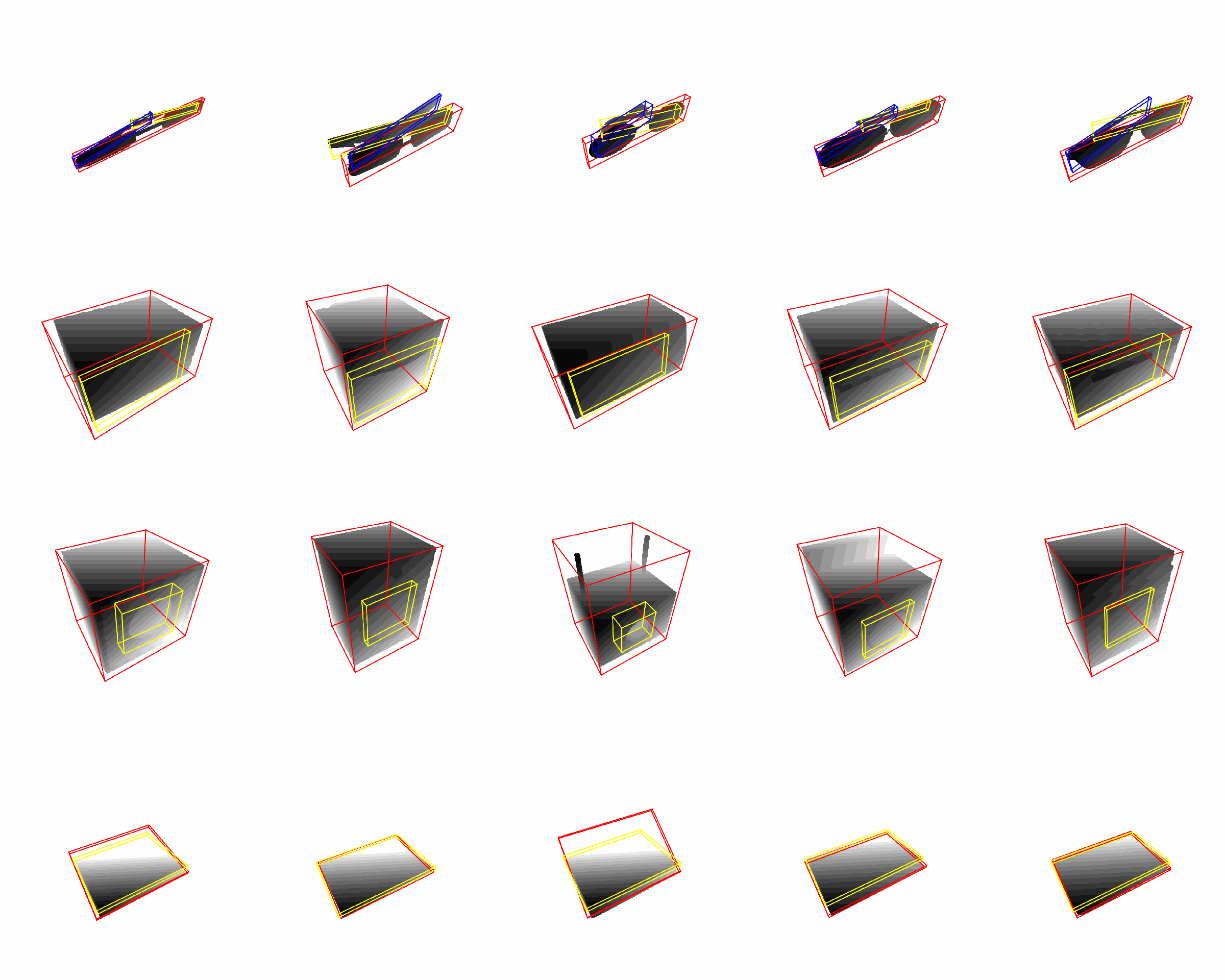
Synthetic Dataset: continuous articulation, fixed view point
Synthetic Dataset: random articulation, random view point
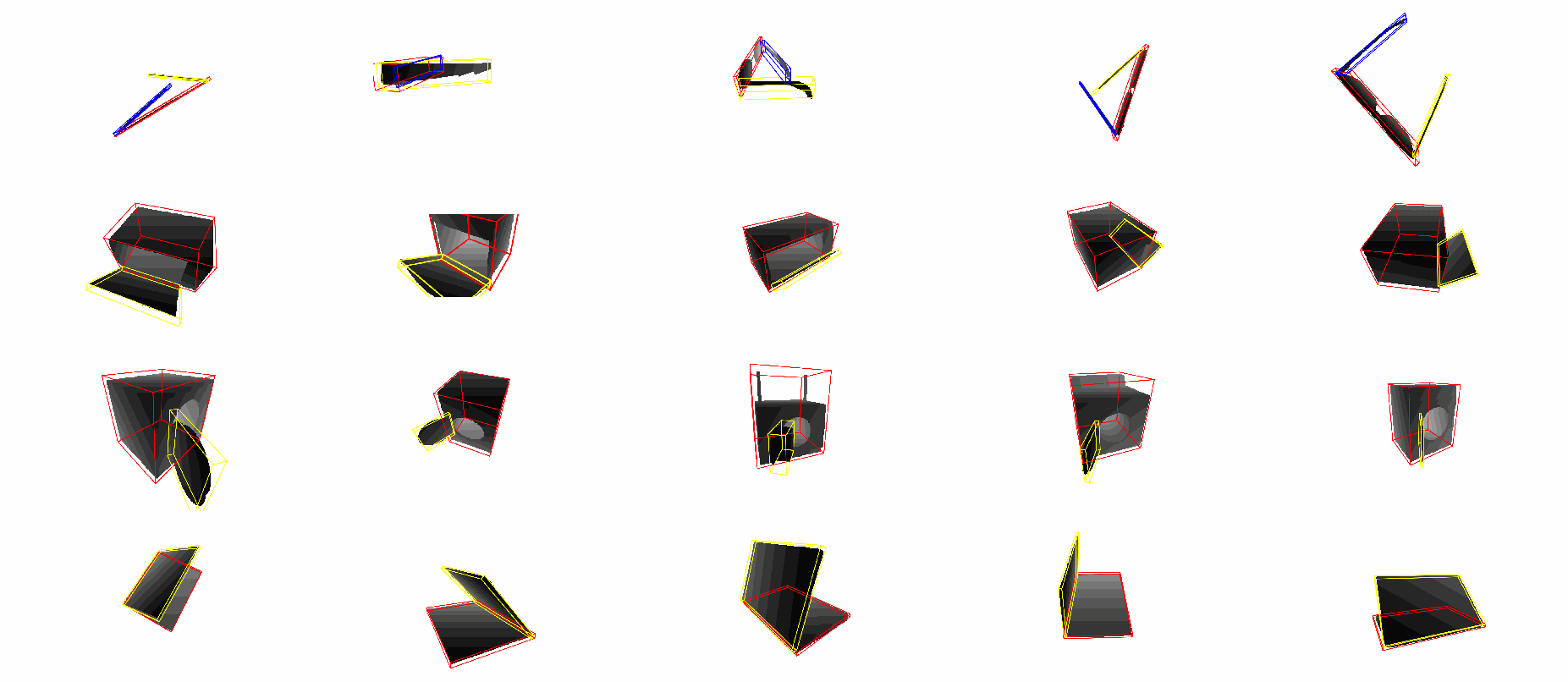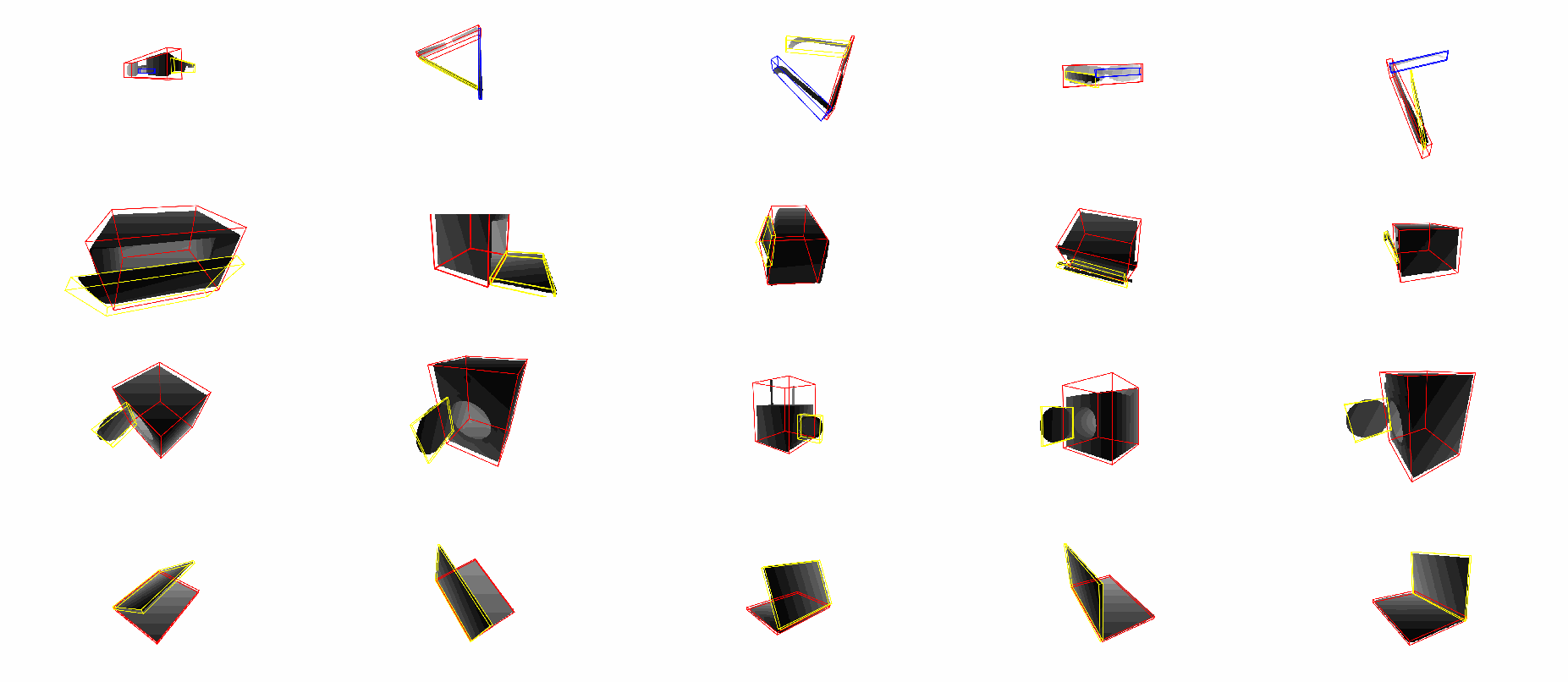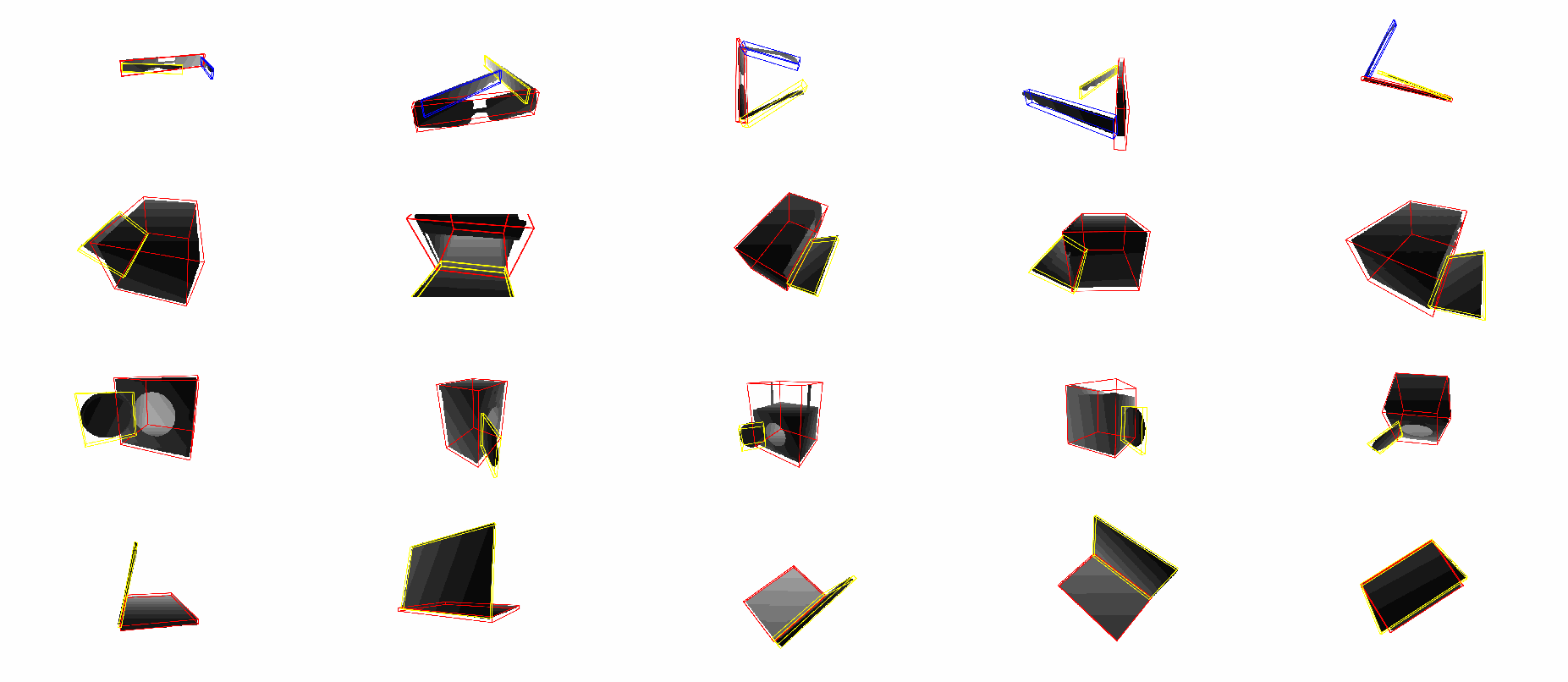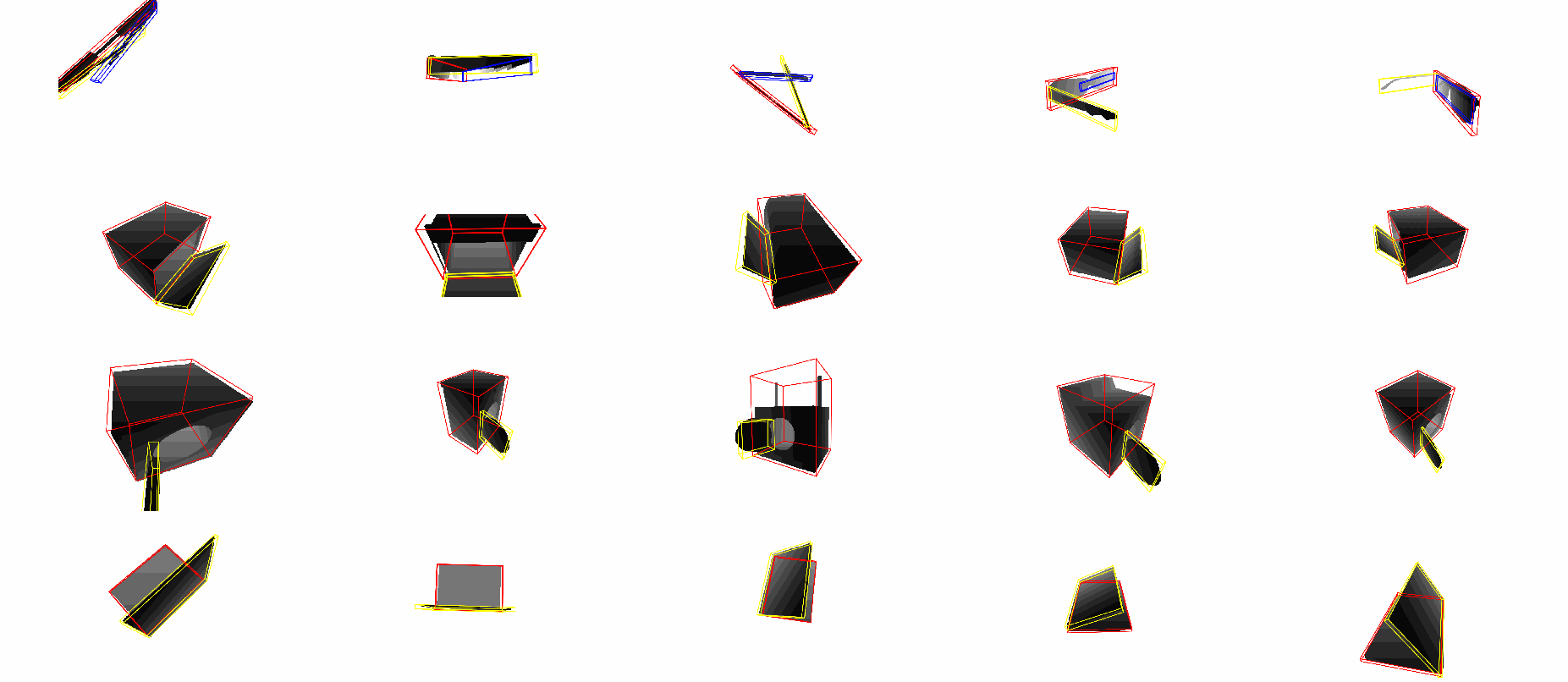
Real Dataset: simu-to-real, instance-level

Paper
Latest version (March 31, 2020): arXiv:1912.11913 in cs.CV or here.

Team






* stands for equal contribution.
Bibtex
@article{li2019articulated-pose,
title={Category-Level Articulated Object Pose Estimation},
author={Li, Xiaolong and Wang, He and Yi, Li and Guibas, Leonidas and Abbott, A. Lynn and Song, Shuran},
journal={arXiv preprint arXiv:1912.11913},
year={2019} }
Acknowledgements
This research was supported by a grant from Toyota-Stanford Center for AI Research. This research used resources provided by Advanced Research Computing within the Division of Information Technology at Virginia Tech. We thank Vision and Learning Lab at Virginia Tech for help on visualization tools. We are also grateful for financial and hardware support from Google.
Contact
If you have any questions, please feel free to contact Xiaolong Li at lxiaol9_at_vt.edu and He Wang at hewang_at_stanford.edu